Rewriting the Beginner’s Guide to SEO, Chapter 6: Link Building & Establishing Authority
Posted by BritneyMullerIn Chapter 6 of the new Beginner’s Guide to SEO, we’ll be covering the dos and don’ts of link building and ways your site can build its authority. If you missed them, we’ve got the drafts of our outline, Chapter One, Chapter Two,…
On-Page SEO for 2019 – Whiteboard Friday
Posted by BritneyMullerWhew! We made it through another year, and it seems like we’re past due for taking a close look at the health of our on-page SEO practices. What better way to hit the ground running than with a checklist? In today’s Whiteboard Fr…
Log File Analysis 101 – Whiteboard Friday
Posted by BritneyMullerLog file analysis can provide some of the most detailed insights about what Googlebot is doing on your site, but it can be an intimidating subject. In this week’s Whiteboard Friday, Britney Muller breaks down log file analysis to…
Rewriting the Beginner’s Guide to SEO, Chapter 5: Technical Optimization
Posted by BritneyMullerAfter a short break, we’re back to share our working draft of Chapter 5 of the Beginner’s Guide to SEO with you! This one was a whopper, and we’re really looking forward to your input. Giving beginner SEOs a solid grasp of just w…
SEO Negotiation: How to Ace the Business Side of SEO – Whiteboard Friday
Posted by BritneyMullerSEO isn’t all meta tags and content. A huge part of the success you’ll see is tied up in the inevitable business negotiations. In this week’s Whiteboard Friday, our resident expert Britney Muller walks us through a bevy of smart …
SEO Negotiation: How to Ace the Business Side of SEO – Whiteboard Friday
Posted by BritneyMullerSEO isn’t all meta tags and content. A huge part of the success you’ll see is tied up in the inevitable business negotiations. In this week’s Whiteboard Friday, our resident expert Britney Muller walks us through a bevy of smart …
Rewriting the Beginner’s Guide to SEO, Chapter 4: On-Page Optimization
Posted by BritneyMuller
Chapter Four of the Beginner’s Guide to SEO rewrite is chock full of on-page SEO learnings. After all the great feedback you’ve provided thus far on our outline, Chapter One, Chapter Two, and Chapter Three, we’re eager to hear how you feel about Chapter Four. What really works for you? What do you think is missing? Read on, and let us know your thoughts in the comments!
Chapter 4: On-Page Optimization
Use your research to craft your message.
Now that you know how your target market is searching, it’s time to dive into on-page optimization, the practice of crafting web pages that answer searcher’s questions. On-page SEO is multifaceted, and extends beyond content into other things like schema and meta tags, which we’ll discuss more at length in the next chapter on technical optimization. For now, put on your wordsmithing hats — it’s time to create your content!
Creating your content
Applying your keyword research
In the last chapter, we learned methods for discovering how your target audience is searching for your content. Now, it’s time to put that research into practice. Here is a simple outline to follow for applying your keyword research:
- Survey your keywords and group those with similar topics and intent. Those groups will be your pages, rather than creating individual pages for every keyword variation.
- If you haven’t done so already, evaluate the SERP for each keyword or group of keywords to determine what type and format your content should be. Some characteristics of ranking pages to take note of:
- Are they image or video heavy?
- Is the content long-form or short and concise?
- Is the content formatted in lists, bullets, or paragraphs?
- Ask yourself, “What unique value could I offer to make my page better than the pages that are currently ranking for my keyword?”
On-page optimization allows you to turn your research into content your audience will love. Just make sure to avoid falling into the trap of low-value tactics that could hurt more than help!
Low-value tactics to avoid
Your web content should exist to answer searchers’ questions, to guide them through your site, and to help them understand your site’s purpose. Content should not be created for the purpose of ranking highly in search alone. Ranking is a means to an end, the end being to help searchers. If we put the cart before the horse, we risk falling into the trap of low-value content tactics.
Some of these tactics were introduced in Chapter 2, but by way of review, let’s take a deeper dive into some low-value tactics you should avoid when crafting search engine optimized content.
Thin content
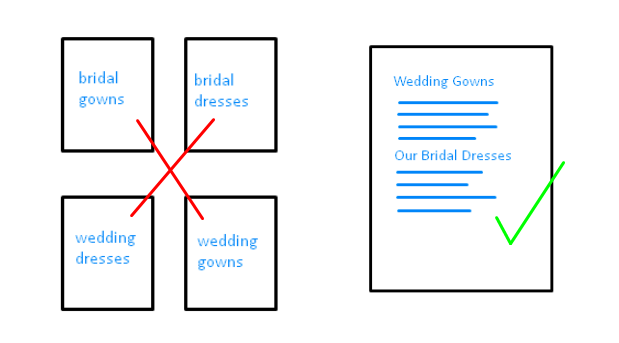
While it’s common for a website to have unique pages on different topics, an older content strategy was to create a page for every single iteration of your keywords in order to rank on page 1 for those highly specific queries.
For example, if you were selling bridal dresses, you might have created individual pages for bridal gowns, bridal dresses, wedding gowns, and wedding dresses, even if each page was essentially saying the same thing. A similar tactic for local businesses was to create multiple pages of content for each city or region from which they wanted clients. These “geo pages” often had the same or very similar content, with the location name being the only unique factor.
Tactics like these clearly weren’t helpful for users, so why did publishers do it? Google wasn’t always as good as it is today at understanding the relationships between words and phrases (or semantics). So, if you wanted to rank on page 1 for “bridal gowns” but you only had a page on “wedding dresses,” that may not have cut it.
This practice created tons of thin, low-quality content across the web, which Google addressed specifically with its 2011 update known as Panda. This algorithm update penalized low-quality pages, which resulted in more quality pages taking the top spots of the SERPs. Google continues to iterate on this process of demoting low-quality content and promoting high-quality content today.
Google is clear that you should have a comprehensive page on a topic instead of multiple, weaker pages for each variation of a keyword.
Duplicate content
Like it sounds, “duplicate content” refers to content that is shared between domains or between multiple pages of a single domain. “Scraped” content goes a step further, and entails the blatant and unauthorized use of content from other sites. This can include taking content and republishing as-is, or modifying it slightly before republishing, without adding any original content or value.
There are plenty of legitimate reasons for internal or cross-domain duplicate content, so Google encourages the use of a rel=canonical tag to point to the original version of the web content. While you don’t need to know about this tag just yet, the main thing to note for now is that your content should be unique in word and in value.

Cloaking
A basic tenet of search engine guidelines is to show the same content to the engine’s crawlers that you’d show to a human visitor. This means that you should never hide text in the HTML code of your website that a normal visitor can’t see.
When this guideline is broken, search engines call it “cloaking” and take action to prevent these pages from ranking in search results. Cloaking can be accomplished in any number of ways and for a variety of reasons, both positive and negative. Below is an example of an instance where Spotify showed different content to users than to Google.
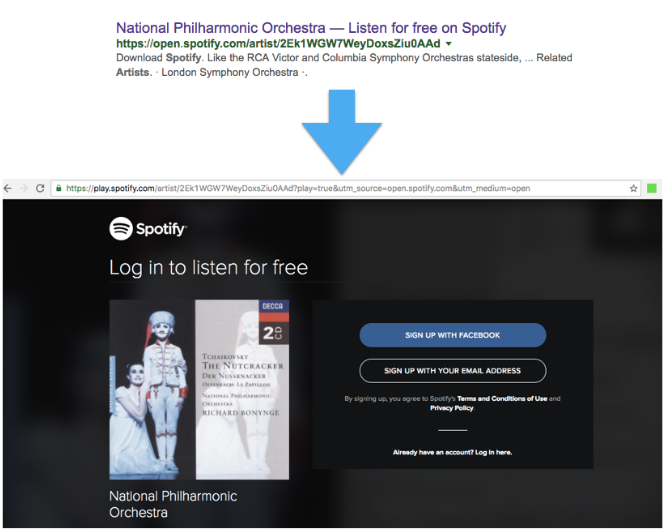
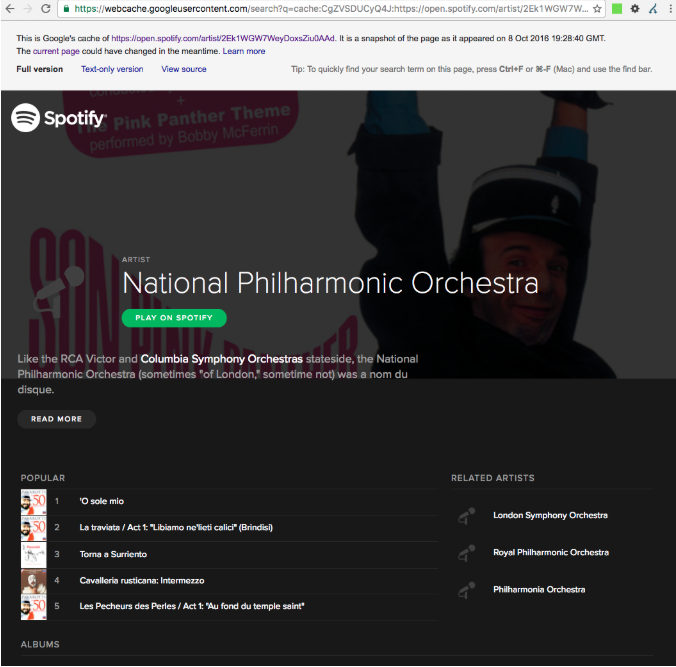
In some cases, Google may let practices that are technically cloaking pass because they contribute to a positive user experience. For more on the subject of cloaking and the levels of risk associated with various tactics, see our article on White Hat Cloaking.
Keyword stuffing
If you’ve ever been told, “You need to include {critical keyword} on this page X times,” you’ve seen the confusion over keyword usage in action. Many people mistakenly think that if you just include a keyword within your page’s content X times, you will automatically rank for it. The truth is, although Google looks for mentions of keywords and related concepts on your site’s pages, the page itself has to add value outside of pure keyword usage. If a page is going to be valuable to users, it won’t sound like it was written by a robot, so incorporate your keywords and phrases naturally in a way that is understandable to your readers.
Below is an example of a keyword-stuffed page of content that also uses another old method: bolding all your targeted keywords. Oy.

Auto-generated content
Arguably one of the most offensive forms of low quality content is the kind that is auto-generated, or created programmatically with the intent of manipulating search rankings and not helping users. You may recognize some auto-generated content by how little it makes sense when read — they are technically words, but strung together by a program rather than a human being.

It is worth noting that advancements in machine learning have contributed to more sophisticated auto-generated content that will only get better over time. This is likely why in Google’s quality guidelines on automatically generated content, Google specifically calls out the brand of auto-generated content that attempts to manipulate search rankings, rather than any-and-all auto-generated content.
What to do instead: 10x it!
There is no “secret sauce” to ranking in search results. Google ranks pages highly because it has determined they are the best answers to the searcher’s questions. In today’s search engine, it’s not enough that your page isn’t duplicate, spamming, or broken. Your page has to provide value to searchers and be better than any other page Google is currently serving as the answer to a particular query. Here’s a simple formula for content creation:
- Search the keyword(s) you want your page to rank for
- Identify which pages are ranking highly for those keywords
- Determine what qualities those pages possess
- Create content that’s better than that
We like to call this 10x content. If you create a page on a keyword that is 10x better than the pages being shown in search results (for that keyword), Google will reward you for it, and better yet, you’ll naturally get people linking to it! Creating 10x content is hard work, but will pay dividends in organic traffic.
Just remember, there’s no magic number when it comes to words on a page. What we should be aiming for is whatever sufficiently satisfies user intent. Some queries can be answered thoroughly and accurately in 300 words while others might require 1,000 words!
Pro tip: Don’t reinvent the wheel!
If you already have content on your website, save yourself time by evaluating which of those pages are already bringing in good amounts of organic traffic and converting well. Refurbish that content on different platforms to help get more visibility to your site. On the other side of the coin, evaluate what existing content isn’t performing as well and adjust it, rather than starting from square one with all new content.
NAP: A note for local businesses
If you’re a business that makes in-person contact with your customers, be sure to include your business name, address, and phone number (NAP) prominently, accurately, and consistently throughout your site’s content. This information is often displayed in the footer or header of a local business website, as well as on any “contact us” pages. You’ll also want to mark up this information using local business schema. Schema and structured data are discussed more at length in the “Code” section of this chapter.
If you are a multi-location business, it’s best to build unique, optimized pages for each location. For example, a business that has locations in Seattle, Tacoma, and Bellevue should consider having a page for each:
example.com/seattle example.com/tacoma example.com/bellevue
Each page should be uniquely optimized for that location, so the Seattle page would have unique content discussing the Seattle location, list the Seattle NAP, and even testimonials specifically from Seattle customers. If there are dozens, hundreds, or even thousands of locations, a store locator widget could be employed to help you scale.
Hope you still have some energy left after handling the difficult-yet-rewarding task of putting together a page that is 10x better than your competitors’ pages, because there are just a few more things needed before your page is complete! In the next sections, we’ll talk about the other on-page optimizations your pages need, as well as naming and organizing your content.
Beyond content: Other optimizations your pages need
Can I just bump up the font size to create paragraph headings?
How can I control what title and description show up for my page in search results?
After reading this section, you’ll understand other important on-page elements that help search engines understand the 10x content you just created, so let’s dive in!
Header tags
Header tags are an HTML element used to designate headings on your page. The main header tag, called an H1, is typically reserved for the title of the page. It looks like this:
<h1>Page Title</h1>
There are also sub-headings that go from H2 (<h2>) to H6 (<h6>) tags, although using all of these on a page is not required. The hierarchy of header tags goes from H1 to H6 in descending order of importance.
Each page should have a unique H1 that describes the main topic of the page, this is often automatically created from the title of a page. As the main descriptive title of the page, the H1 should contain that page’s primary keyword or phrase. You should avoid using header tags to mark up non-heading elements, such as navigational buttons and phone numbers. Use header tags to introduce what the following content will discuss.
Take this page about touring Copenhagen, for example:
<h1>Copenhagen Travel Guide</h1> <h2>Copenhagen by the Seasons</h2> <h3>Visiting in Winter</h3> <h3>Visiting in Spring</h3>
The main topic of the page is introduced in the main <h1> heading, and each additional heading is used to introduce a new sub-topic. In this example, the <h2> is more specific than the <h1>, and the <h3> tags are more specific than the <h2>. This is just an example of a structure you could use.
Although what you choose to put in your header tags can be used by search engines to evaluate and rank your page, it’s important to avoid inflating their importance. Header tags are one among many on-page SEO factors, and typically would not move the needle like quality backlinks and content would, so focus on your site visitors when crafting your headings.
Internal links
In Chapter 2, we discussed the importance of having a crawlable website. Part of a website’s crawlability lies in its internal linking structure. When you link to other pages on your website, you ensure that search engine crawlers can find all your site’s pages, you pass link equity (ranking power) to other pages on your site, and you help visitors navigate your site.
The importance of internal linking is well established, but there can be confusion over how this looks in practice.
Link accessibility
Links that require a click (like a navigation drop-down to view) are often hidden from search engine crawlers, so if the only links to internal pages on your website are through these types of links, you may have trouble getting those pages indexed. Opt instead for links that are directly accessible on the page.
Anchor text
Anchor text is the text with which you link to pages. Below, you can see an example of what a hyperlink without anchor text and a hyperlink with anchor text would look like in the HTML.
<a href="http://www.domain.com/"></a> <a href="http://www.domain.com/" title="Keyword Text">Keyword Text</a>
On live view, that would look like this:
The anchor text sends signals to search engines regarding the content of the destination page. For example, if I link to a page on my site using the anchor text “learn SEO,” that’s a good indicator to search engines that the targeted page is one at which people can learn about SEO. Be careful not to overdo it, though. Too many internal links using the same, keyword-stuffed anchor text can appear to search engines that you’re trying to manipulate a page’s ranking. It’s best to make anchor text natural rather than formulaic.
Link volume
In Google’s General Webmaster Guidelines, they say to “limit the number of links on a page to a reasonable number (a few thousand at most).” This is part of Google’s technical guidelines, rather than the quality guideline section, so having too many internal links isn’t something that on its own is going to get you penalized, but it does affect how Google finds and evaluates your pages.
The more links on a page, the less equity each link can pass to its destination page. A page only has so much equity to go around.
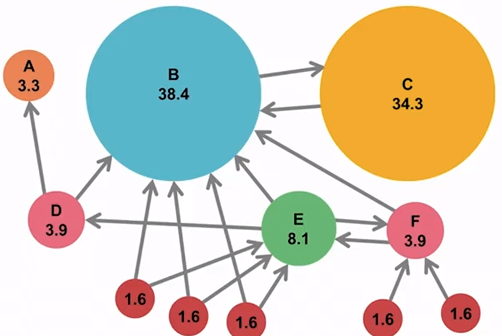
So it’s safe to say that you should only link when you mean it! You can learn more about link equity from our SEO Learning Center.
Aside from passing authority between pages, a link is also a way to help users navigate to other pages on your site. This is a case where doing what’s best for search engines is also doing what’s best for searchers. Too many links not only dilute the authority of each link, but they can also be unhelpful and overwhelming. Consider how a searcher might feel landing on a page that looks like this:
Welcome to our gardening website! We have many articles on gardening, how to garden, and helpful tips on herbs, fruits, vegetables, perennials, and annuals. Learn more about gardening from our gardening blog.
Whew! Not only is that a lot of links to process, but it also reads pretty unnaturally and doesn’t contain much substance (which could be considered “thin content” by Google). Focus on quality and helping your users navigate your site, and you likely won’t have to worry about too many links.
Redirection
Removing and renaming pages is a common practice, but in the event that you do move a page, make sure to update the links to that old URL! At the very least, you should make sure to redirect the URL to its new location, but if possible, update all internal links to that URL at the source so that users and crawlers don’t have to pass through redirects to arrive at the destination page. If you choose to redirect only, be careful to avoid redirect chains that are too long (Google says, “Avoid chaining redirects… keep the number of redirects in the chain low, ideally no more than 3 and fewer than 5.”)
Example of a redirect chain:
(original location of content) example.com/location1 >> example.com/location2 >> (current location of content) example.com/location3
Better:
example.com/location1 >> example.com/location3
Image optimization
Images are the biggest culprits of slow web pages! The best way to solve for this is to compress your images. While there is no one-size-fits-all when it comes to image compression, testing various options like “save for web,” image sizing, and compression tools like Optimizilla, ImageOptim for Mac (or Windows alternatives), as well as evaluating what works best is the way to go.
Another way to help optimize your images (and improve your page speed) is by choosing the right image format.
How to choose which image format to use:
 Source: Google’s image optimization guide
Source: Google’s image optimization guide
Choosing image formats:
- If your image requires animation, use a GIF.
- If you don’t need to preserve high image resolution, use JPEG (and test out different compression settings).
- If you do need to preserve high image resolution, use PNG.
- If your image has a lot of colors, use PNG-24.
- If your image doesn’t have a lot of colors, use PNG-8.
There are different ways to keep visitors on a semi-slow loading page by using images that produce a colored box or a very blurry/low resolution version while rendering to help visitors feel as if things are loading faster. We will discuss these options in more detail in Chapter 5.
Pro tip: Don’t forget about thumbnails!
Thumbnails (especially for E-Commerce sites) can be a huge page speed slow down. Optimize thumbnails properly to avoid slow pages and to help retain more qualified visitors.
Alt text
Alt text (alternative text) within images is a principle of web accessibility, and is used to describe images to the visually impaired via screen readers. It’s important to have alt text descriptions so that any visually impaired person can understand what the pictures on your website depict.
Search engine bots also crawl alt text to better understand your images, which gives you the added benefit of providing better image context to search engines. Just ensure that your alt descriptions reads naturally for people, and avoid stuffing keywords for search engines.
Bad:
<img src="grumpycat.gif" alt="grumpy cat, cat is grumpy, grumpy cat gif">
Good:
<img src="grumpycat.gif" alt="A black cat looking very grumpy at a big spotted dog">
Submit an image sitemap
To ensure that Google can crawl and index your images, submit an image sitemap in your Google Search Console account. This helps Google discover images they may have otherwise missed.
Formatting for readability & featured snippets
Your page could contain the best content ever written on a subject, but if it’s formatted improperly, your audience might never read it! While we can never guarantee that visitors will read our content, there are some principles that can promote readability, including:
- Text size and color – Avoid fonts that are too tiny. Google recommends 16+px font to minimize the need for “pinching and zooming” on mobile. The text color in relation to the page’s background color should also promote readability. Additional information on text can be found in the website accessibility guidelines. (Google’s web accessibility fundamentals).
- Headings – Breaking up your content with helpful headings can help readers navigate the page. This is especially useful on long pages where a reader might be looking only for information from a particular section.
- Bullet points – Great for lists, bullet points can help readers skim and more quickly find the information they need.
- Paragraph breaks – Avoiding walls of text can help prevent page abandonment and encourage site visitors to read more of your page.
- Supporting media – When appropriate, include images, videos, and widgets that would complement your content.
- Bold and italics for emphasis – Putting words in bold or italics can add emphasis, so they should be the exception, not the rule. Appropriate use of these formatting options can call out important points you want to communicate.
Formatting can also affect your page’s ability to show up in featured snippets, those “position 0” results that appear above the rest of organic results.
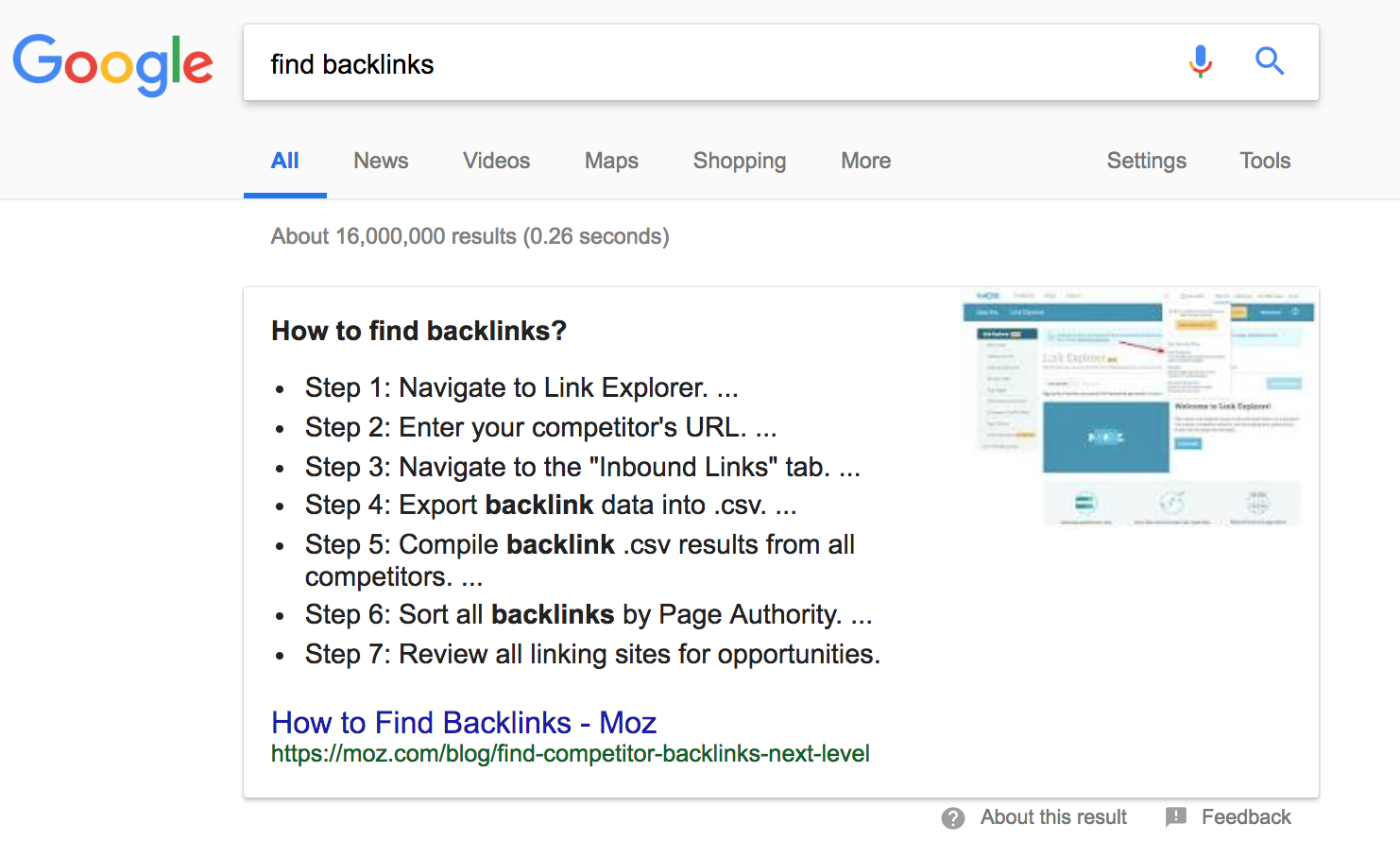
There is no special code that you can add to your page to show up here, nor can you pay for this placement, but taking note of the query intent can help you better structure your content for featured snippets. For example, if you’re trying to rank for “cake vs. pie,” it might make sense to include a table in your content, with the benefits of cake in one column and the benefits of pie in the other. Or if you’re trying to rank for “best restaurants to try in Portland,” that could indicate Google wants a list, so formatting your content in bullets could help.
Title tags
A page’s title tag is a descriptive, HTML element that specifies the title of a particular web page. They are nested within the head tag of each page and look like this:
<head> <title>Example Title</title> </head>
Each page on your website should have a unique, descriptive title tag. What you input into your title tag field will show up here in search results, although in some cases Google may adjust how your title tag appears in search results.

It can also show up in web browsers…

Or when you share the link to your page on certain external websites…

Your title tag has a big role to play in people’s first impression of your website, and it’s an incredibly effective tool for drawing searchers to your page over any other result on the SERP. The more compelling your title tag, combined with high rankings in search results, the more visitors you’ll attract to your website. This underscores that SEO is not only about search engines, but rather the entire user experience.
What makes an effective title tag?
- Keyword usage: Having your target keyword in the title can help both users and search engines understand what your page is about. Also, the closer to the front of the title tag your keywords are, the more likely a user will be to read them (and hopefully click) and the more helpful they can be for ranking.
- Length: On average, search engines display the first 50–60 characters (~512 pixels) of a title tag in search results. If your title tag exceeds the characters allowed on that SERP, an ellipsis “…” will appear where the title was cut off. While sticking to 50–60 characters is safe, never sacrifice quality for strict character counts. If you can’t get your title tag down to 60 characters without harming its readability, go longer (within reason).
- Branding: At Moz, we love to end our title tags with a brand name mention because it promotes brand awareness and creates a higher click-through rate among people who are familiar with Moz. Sometimes it makes sense to place your brand at the beginning of the title tag, such as on your homepage, but be mindful of what you are trying to rank for and place those words closer toward the beginning of your title tag.



Meta descriptions
Like title tags, meta descriptions are HTML elements that describe the contents of the page that they’re on. They are also nested in the head tag, and look like this:
<head> <meta name=”description” content=”Description of page here.”/> </head>
What you input into the description field will show up here in search results:

In many cases though, Google will choose different snippets of text to display in search results, dependent upon the searcher’s query.
For example if you search “find backlinks,” Google will provide this meta description as it deems it more relevant to the specific search:
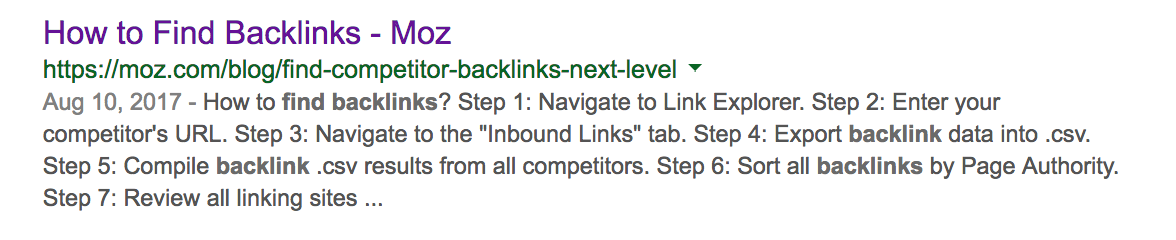
While the actual meta description is:

This often helps to improve your meta descriptions for unique searches. However, don’t let this deter you from writing a default page meta description — they’re still extremely valuable.
What makes an effective meta description?
The qualities that make an effective title tag also apply to effective meta descriptions. Although Google says that meta descriptions are not a ranking factor, like title tags, they are incredibly important for click-through rate.
- Relevance: Meta descriptions should be highly relevant to the content of your page, so it should summarize your key concept in some form. You should give the searcher enough information to know they’ve found a page relevant enough to answer their question, without giving away so much information that it eliminates the need to click through to your web page.
- Length: Search engines tend to truncate meta descriptions to around 300 characters. It’s best to write meta descriptions between 150–300 characters in length. On some SERPs, you’ll notice that Google gives much more real estate to the descriptions of some pages. This usually happens for web pages ranking right below a featured snippet.
URL structure: Naming and organizing your pages
URL stands for Uniform Resource Locator. URLs are the locations or addresses for individual pieces of content on the web. Like title tags and meta descriptions, search engines display URLs on the SERPs, so URL naming and format can impact click-through rates. Not only do searchers use them to make decisions about which web pages to click on, but URLs are also used by search engines in evaluating and ranking pages.
Clear page naming
Search engines require unique URLs for each page on your website so they can display your pages in search results, but clear URL structure and naming is also helpful for people who are trying to understand what a specific URL is about. For example, which URL is clearer?
example.com/desserts/chocolate-pie
OR
example.com/asdf/453?=recipe-23432-1123
Searchers are more likely to click on URLs that reinforce and clarify what information is contained on that page, and less likely to click on URLs that confuse them.
Page organization
If you discuss multiple topics on your website, you should also make sure to avoid nesting pages under irrelevant folders. For example:
example.com/commercial-litigation/alimony
It would have been better for this fictional multi-practice law firm website to nest alimony under “/family-law/” than to host it under the irrelevant “/commercial-litigation/” section of the website.
The folders in which you locate your content can also send signals about the type, not just the topic, of your content. For example, dated URLs can indicate time-sensitive content. While appropriate for news-based websites, dated URLs for evergreen content can actually turn searchers away because the information seems outdated. For example:
example.com/2015/april/what-is-seo/
vs.
example.com/what-is-seo/
Since the topic “What is SEO?” isn’t confined to a specific date, it’s best to host on a non-dated URL structure or else risk your information appearing stale.
As you can see, what you name your pages, and in what folders you choose to organize your pages, is an important way to clarify the topic of your page to users and search engines.
URL length
While it is not necessary to have a completely flat URL structure, many click-through rate studies indicate that, when given the choice between a URL and a shorter URL, searchers often prefer shorter URLs. Like title tags and meta descriptions that are too long, too-long URLs will also be cut off with an ellipsis. Just remember, having a descriptive URL is just as important, so don’t cut down on URL length if it means sacrificing the URL’s descriptiveness.
example.com/services/plumbing/plumbing-repair/toilets/leaks/
vs.
example.com/plumbing-repair/toilets/
Minimizing length, both by including fewer words in your page names and removing unnecessary subfolders, makes your URLs easier to copy and paste, as well as more clickable.
Keywords in URL
If your page is targeting a specific term or phrase, make sure to include it in the URL. However, don’t go overboard by trying to stuff in multiple keywords for purely SEO purposes. It’s also important to watch out for repeat keywords in different subfolders. For example, you may have naturally incorporated a keyword into a page name, but if located within other folders that are also optimized with that keyword, the URL could begin to appear keyword-stuffed.
Example:
example.com/seattle-dentist/dental-services/dental-crowns/
Keyword overuse in URLs can appear spammy and manipulative. If you aren’t sure whether your keyword usage is too aggressive, just read your URL through the eyes of a searcher and ask, “Does this look natural? Would I click on this?”
Static URLs
The best URLs are those that can easily be read by humans, so you should avoid the overuse of parameters, numbers, and symbols. Using technologies like mod_rewrite for Apache and ISAPI_rewrite for Microsoft, you can easily transform dynamic URLs like this:
into a more readable static version like this:
https://moz.com/google-algorithm-change
Hyphens for word separation
Not all web applications accurately interpret separators like underscores (_), plus signs (+), or spaces (%20). Search engines also do not understand how to separate words in URLs when they run together without a separator (example.com/optimizefeaturedsnippets/). Instead, use the hyphen character (-) to separate words in a URL.
Geographic Modifiers in URLs
Some local business owners omit geographic terms that describe their physical location or service area because they believe that search engines can figure this out on their own. On the contrary, it’s vital that local business websites’ content, URLs, and other on-page assets make specific mention of city names, neighborhood names, and other regional descriptors. Let both consumers and search engines know exactly where you are and where you serve, rather than relying on your physical location alone.
Protocols: HTTP vs. HTTPS
A protocol is that “http” or “https” preceding your domain name. Google recommends that all websites have a secure protocol (the “s” in “https” stands for “secure”). To ensure that your URLs are using the https:// protocol instead of http://, you must obtain an SSL (Secure Sockets Layer) certificate. SSL certificates are used to encrypt data. They ensure that any data passed between the web server and browser of the searcher remains private. As of July 2018, Google Chrome displays “not secure” for all HTTP sites, which could cause these sites to appear untrustworthy to visitors and result in them leaving the site.

If you’ve made it this far, congratulations on surpassing the halfway point of the Beginner’s Guide to SEO! So far, we’ve learned how search engines crawl, index, and rank content, how to find keyword opportunities to target, and now, you know the on-page optimization strategies that can help your pages get found. Next, buckle up, because we’ll be diving into the exciting world of technical SEO!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Rewriting the Beginner’s Guide to SEO, Chapter 3: Keyword Research
Posted by BritneyMullerWelcome to the draft of Chapter Three of the new and improved Beginner’s Guide to SEO! So far you’ve been generous and energizing with your feedback for our outline, Chapter One, and Chapter Two. We’re asking for a little more of…
Rewriting the Beginner’s Guide to SEO, Chapter 2: Crawling, Indexing, and Ranking
Posted by BritneyMuller
It’s been a few months since our last share of our work-in-progress rewrite of the Beginner’s Guide to SEO, but after a brief hiatus, we’re back to share our draft of Chapter Two with you! This wouldn’t have been possible without the help of Kameron Jenkins, who has thoughtfully contributed her great talent for wordsmithing throughout this piece.
This is your resource, the guide that likely kicked off your interest in and knowledge of SEO, and we want to do right by you. You left amazingly helpful commentary on our outline and draft of Chapter One, and we’d be honored if you would take the time to let us know what you think of Chapter Two in the comments below.
Chapter 2: How Search Engines Work – Crawling, Indexing, and Ranking
First, show up.
As we mentioned in Chapter 1, search engines are answer machines. They exist to discover, understand, and organize the internet’s content in order to offer the most relevant results to the questions searchers are asking.
In order to show up in search results, your content needs to first be visible to search engines. It’s arguably the most important piece of the SEO puzzle: If your site can’t be found, there’s no way you’ll ever show up in the SERPs (Search Engine Results Page).
How do search engines work?
Search engines have three primary functions:
- Crawl: Scour the Internet for content, looking over the code/content for each URL they find.
- Index: Store and organize the content found during the crawling process. Once a page is in the index, it’s in the running to be displayed as a result to relevant queries.
- Rank: Provide the pieces of content that will best answer a searcher’s query. Order the search results by the most helpful to a particular query.
What is search engine crawling?
Crawling, is the discovery process in which search engines send out a team of robots (known as crawlers or spiders) to find new and updated content. Content can vary — it could be a webpage, an image, a video, a PDF, etc. — but regardless of the format, content is discovered by links.
The bot starts out by fetching a few web pages, and then follows the links on those webpages to find new URLs. By hopping along this path of links, crawlers are able to find new content and add it to their index — a massive database of discovered URLs — to later be retrieved when a searcher is seeking information that the content on that URL is a good match for.
What is a search engine index?
Search engines process and store information they find in an index, a huge database of all the content they’ve discovered and deem good enough to serve up to searchers.
Search engine ranking
When someone performs a search, search engines scour their index for highly relevant content and then orders that content in the hopes of solving the searcher’s query. This ordering of search results by relevance is known as ranking. In general, you can assume that the higher a website is ranked, the more relevant the search engine believes that site is to the query.
It’s possible to block search engine crawlers from part or all of your site, or instruct search engines to avoid storing certain pages in their index. While there can be reasons for doing this, if you want your content found by searchers, you have to first make sure it’s accessible to crawlers and is indexable. Otherwise, it’s as good as invisible.
By the end of this chapter, you’ll have the context you need to work with the search engine, rather than against it!
Note: In SEO, not all search engines are equal
Many beginners wonder about the relative importance of particular search engines. Most people know that Google has the largest market share, but how important it is to optimize for Bing, Yahoo, and others? The truth is that despite the existence of more than 30 major web search engines, the SEO community really only pays attention to Google. Why? The short answer is that Google is where the vast majority of people search the web. If we include Google Images, Google Maps, and YouTube (a Google property), more than 90% of web searches happen on Google — that’s nearly 20 times Bing and Yahoo combined.
Crawling: Can search engines find your site?
As you’ve just learned, making sure your site gets crawled and indexed is a prerequisite for showing up in the SERPs. First things first: You can check to see how many and which pages of your website have been indexed by Google using “site:yourdomain.com“, an advanced search operator.
Head to Google and type “site:yourdomain.com” into the search bar. This will return results Google has in its index for the site specified:

The number of results Google displays (see “About __ results” above) isn’t exact, but it does give you a solid idea of which pages are indexed on your site and how they are currently showing up in search results.
For more accurate results, monitor and use the Index Coverage report in Google Search Console. You can sign up for a free Google Search Console account if you don’t currently have one. With this tool, you can submit sitemaps for your site and monitor how many submitted pages have actually been added to Google’s index, among other things.
If you’re not showing up anywhere in the search results, there are a few possible reasons why:
- Your site is brand new and hasn’t been crawled yet.
- Your site isn’t linked to from any external websites.
- Your site’s navigation makes it hard for a robot to crawl it effectively.
- Your site contains some basic code called crawler directives that is blocking search engines.
- Your site has been penalized by Google for spammy tactics.
If your site doesn’t have any other sites linking to it, you still might be able to get it indexed by submitting your XML sitemap in Google Search Console or manually submitting individual URLs to Google. There’s no guarantee they’ll include a submitted URL in their index, but it’s worth a try!
Can search engines see your whole site?
Sometimes a search engine will be able to find parts of your site by crawling, but other pages or sections might be obscured for one reason or another. It’s important to make sure that search engines are able to discover all the content you want indexed, and not just your homepage.
Ask yourself this: Can the bot crawl through your website, and not just to it?
Is your content hidden behind login forms?
If you require users to log in, fill out forms, or answer surveys before accessing certain content, search engines won’t see those protected pages. A crawler is definitely not going to log in.
Are you relying on search forms?
Robots cannot use search forms. Some individuals believe that if they place a search box on their site, search engines will be able to find everything that their visitors search for.
Is text hidden within non-text content?
Non-text media forms (images, video, GIFs, etc.) should not be used to display text that you wish to be indexed. While search engines are getting better at recognizing images, there’s no guarantee they will be able to read and understand it just yet. It’s always best to add text within the <HTML> markup of your webpage.
Can search engines follow your site navigation?
Just as a crawler needs to discover your site via links from other sites, it needs a path of links on your own site to guide it from page to page. If you’ve got a page you want search engines to find but it isn’t linked to from any other pages, it’s as good as invisible. Many sites make the critical mistake of structuring their navigation in ways that are inaccessible to search engines, hindering their ability to get listed in search results.
Common navigation mistakes that can keep crawlers from seeing all of your site:
- Having a mobile navigation that shows different results than your desktop navigation
- Any type of navigation where the menu items are not in the HTML, such as JavaScript-enabled navigations. Google has gotten much better at crawling and understanding Javascript, but it’s still not a perfect process. The more surefire way to ensure something gets found, understood, and indexed by Google is by putting it in the HTML.
- Personalization, or showing unique navigation to a specific type of visitor versus others, could appear to be cloaking to a search engine crawler
- Forgetting to link to a primary page on your website through your navigation — remember, links are the paths crawlers follow to new pages!
This is why it’s essential that your website has a clear navigation and helpful URL folder structures.
Information architecture
Information architecture is the practice of organizing and labeling content on a website to improve efficiency and fundability for users. The best information architecture is intuitive, meaning that users shouldn’t have to think very hard to flow through your website or to find something.
Your site should also have a useful 404 (page not found) page for when a visitor clicks on a dead link or mistypes a URL. The best 404 pages allow users to click back into your site so they don’t bounce off just because they tried to access a nonexistent link.

Tell search engines how to crawl your site
In addition to making sure crawlers can reach your most important pages, it’s also pertinent to note that you’ll have pages on your site you don’t want them to find. These might include things like old URLs that have thin content, duplicate URLs (such as sort-and-filter parameters for e-commerce), special promo code pages, staging or test pages, and so on.
Blocking pages from search engines can also help crawlers prioritize your most important pages and maximize your crawl budget (the average number of pages a search engine bot will crawl on your site).
Crawler directives allow you to control what you want Googlebot to crawl and index using a robots.txt file, meta tag, sitemap.xml file, or Google Search Console.
Robots.txt
Robots.txt files are located in the root directory of websites (ex. yourdomain.com/robots.txt) and suggest which parts of your site search engines should and shouldn’t crawl via specific robots.txt directives. This is a great solution when trying to block search engines from non-private pages on your site.
You wouldn’t want to block private/sensitive pages from being crawled here because the file is easily accessible by users and bots.
Pro tip:
- If Googlebot can’t find a robots.txt file for a site (40X HTTP status code), it proceeds to crawl the site.
- If Googlebot finds a robots.txt file for a site (20X HTTP status code), it will usually abide by the suggestions and proceed to crawl the site.
- If Googlebot finds neither a 20X or a 40X HTTP status code (ex. a 501 server error) it can’t determine if you have a robots.txt file or not and won’t crawl your site.
Meta directives
The two types of meta directives are the meta robots tag (more commonly used) and the x-robots-tag. Each provides crawlers with stronger instructions on how to crawl and index a URL’s content.
The x-robots tag provides more flexibility and functionality if you want to block search engines at scale because you can use regular expressions, block non-HTML files, and apply sitewide noindex tags.
These are the best options for blocking more sensitive*/private URLs from search engines.
*For very sensitive URLs, it is best practice to remove them from or require a secure login to view the pages.
WordPress Tip: In Dashboard > Settings > Reading, make sure the “Search Engine Visibility” box is not checked. This blocks search engines from coming to your site via your robots.txt file!
Avoid these common pitfalls, and you’ll have clean, crawlable content that will allow bots easy access to your pages.
Once you’ve ensured your site has been crawled, the next order of business is to make sure it can be indexed. That’s right — just because your site can be discovered and crawled by a search engine doesn’t necessarily mean that it will be stored in their index. Read on to learn about how indexing works and how you can make sure your site makes it into this all-important database.
Sitemaps
A sitemap is just what it sounds like: a list of URLs on your site that crawlers can use to discover and index your content. One of the easiest ways to ensure Google is finding your highest priority pages is to create a file that meets Google’s standards and submit it through Google Search Console. While submitting a sitemap doesn’t replace the need for good site navigation, it can certainly help crawlers follow a path to all of your important pages.
Google Search Console
Some sites (most common with e-commerce) make the same content available on multiple different URLs by appending certain parameters to URLs. If you’ve ever shopped online, you’ve likely narrowed down your search via filters. For example, you may search for “shoes” on Amazon, and then refine your search by size, color, and style. Each time you refine, the URL changes slightly. How does Google know which version of the URL to serve to searchers? Google does a pretty good job at figuring out the representative URL on its own, but you can use the URL Parameters feature in Google Search Console to tell Google exactly how you want them to treat your pages.

Indexing: How do search engines understand and remember your site?
Once you’ve ensured your site has been crawled, the next order of business is to make sure it can be indexed. That’s right — just because your site can be discovered and crawled by a search engine doesn’t necessarily mean that it will be stored in their index. In the previous section on crawling, we discussed how search engines discover your web pages. The index is where your discovered pages are stored. After a crawler finds a page, the search engine renders it just like a browser would. In the process of doing so, the search engine analyzes that page’s contents. All of that information is stored in its index.
Read on to learn about how indexing works and how you can make sure your site makes it into this all-important database.
Can I see how a Googlebot crawler sees my pages?
Yes, the cached version of your page will reflect a snapshot of the last time googlebot crawled it.
Google crawls and caches web pages at different frequencies. More established, well-known sites that post frequently like https://www.nytimes.com will be crawled more frequently than the much-less-famous website for Roger the Mozbot’s side hustle, http://www.rogerlovescupcakes.com (if only it were real…)
You can view what your cached version of a page looks like by clicking the drop-down arrow next to the URL in the SERP and choosing “Cached”:
 You can also view the text-only version of your site to determine if your important content is being crawled and cached effectively.
You can also view the text-only version of your site to determine if your important content is being crawled and cached effectively.
Are pages ever removed from the index?
Yes, pages can be removed from the index! Some of the main reasons why a URL might be removed include:
- The URL is returning a “not found” error (4XX) or server error (5XX) – This could be accidental (the page was moved and a 301 redirect was not set up) or intentional (the page was deleted and 404ed in order to get it removed from the index)
- The URL had a noindex meta tag added – This tag can be added by site owners to instruct the search engine to omit the page from its index.
- The URL has been manually penalized for violating the search engine’s Webmaster Guidelines and, as a result, was removed from the index.
- The URL has been blocked from crawling with the addition of a password required before visitors can access the page.
If you believe that a page on your website that was previously in Google’s index is no longer showing up, you can manually submit the URL to Google by navigating to the “Submit URL” tool in Search Console.
Ranking: How do search engines rank URLs?
How do search engines ensure that when someone types a query into the search bar, they get relevant results in return? That process is known as ranking, or the ordering of search results by most relevant to least relevant to a particular query.
To determine relevance, search engines use algorithms, a process or formula by which stored information is retrieved and ordered in meaningful ways. These algorithms have gone through many changes over the years in order to improve the quality of search results. Google, for example, makes algorithm adjustments every day — some of these updates are minor quality tweaks, whereas others are core/broad algorithm updates deployed to tackle a specific issue, like Penguin to tackle link spam. Check out our Google Algorithm Change History for a list of both confirmed and unconfirmed Google updates going back to the year 2000.
Why does the algorithm change so often? Is Google just trying to keep us on our toes? While Google doesn’t always reveal specifics as to why they do what they do, we do know that Google’s aim when making algorithm adjustments is to improve overall search quality. That’s why, in response to algorithm update questions, Google will answer with something along the lines of: “We’re making quality updates all the time.” This indicates that, if your site suffered after an algorithm adjustment, compare it against Google’s Quality Guidelines or Search Quality Rater Guidelines, both are very telling in terms of what search engines want.
What do search engines want?
Search engines have always wanted the same thing: to provide useful answers to searcher’s questions in the most helpful formats. If that’s true, then why does it appear that SEO is different now than in years past?
Think about it in terms of someone learning a new language.
At first, their understanding of the language is very rudimentary — “See Spot Run.” Over time, their understanding starts to deepen, and they learn semantics—- the meaning behind language and the relationship between words and phrases. Eventually, with enough practice, the student knows the language well enough to even understand nuance, and is able to provide answers to even vague or incomplete questions.
When search engines were just beginning to learn our language, it was much easier to game the system by using tricks and tactics that actually go against quality guidelines. Take keyword stuffing, for example. If you wanted to rank for a particular keyword like “funny jokes,” you might add the words “funny jokes” a bunch of times onto your page, and make it bold, in hopes of boosting your ranking for that term:
Welcome to funny jokes! We tell the funniest jokes in the world. Funny jokes are fun and crazy. Your funny joke awaits. Sit back and read funny jokes because funny jokes can make you happy and funnier. Some funny favorite funny jokes.
This tactic made for terrible user experiences, and instead of laughing at funny jokes, people were bombarded by annoying, hard-to-read text. It may have worked in the past, but this is never what search engines wanted.
The role links play in SEO
When we talk about links, we could mean two things. Backlinks or “inbound links” are links from other websites that point to your website, while internal links are links on your own site that point to your other pages (on the same site).
Links have historically played a big role in SEO. Very early on, search engines needed help figuring out which URLs were more trustworthy than others to help them determine how to rank search results. Calculating the number of links pointing to any given site helped them do this.
Backlinks work very similarly to real life WOM (Word-Of-Mouth) referrals. Let’s take a hypothetical coffee shop, Jenny’s Coffee, as an example:
- Referrals from others = good sign of authority
Example: Many different people have all told you that Jenny’s Coffee is the best in town - Referrals from yourself = biased, so not a good sign of authority
Example: Jenny claims that Jenny’s Coffee is the best in town - Referrals from irrelevant or low-quality sources = not a good sign of authority and could even get you flagged for spam
Example: Jenny paid to have people who have never visited her coffee shop tell others how good it is. - No referrals = unclear authority
Example: Jenny’s Coffee might be good, but you’ve been unable to find anyone who has an opinion so you can’t be sure.
This is why PageRank was created. PageRank (part of Google’s core algorithm) is a link analysis algorithm named after one of Google’s founders, Larry Page. PageRank estimates the importance of a web page by measuring the quality and quantity of links pointing to it. The assumption is that the more relevant, important, and trustworthy a web page is, the more links it will have earned.
The more natural backlinks you have from high-authority (trusted) websites, the better your odds are to rank higher within search results.
The role content plays in SEO
There would be no point to links if they didn’t direct searchers to something. That something is content! Content is more than just words; it’s anything meant to be consumed by searchers — there’s video content, image content, and of course, text. If search engines are answer machines, content is the means by which the engines deliver those answers.
Any time someone performs a search, there are thousands of possible results, so how do search engines decide which pages the searcher is going to find valuable? A big part of determining where your page will rank for a given query is how well the content on your page matches the query’s intent. In other words, does this page match the words that were searched and help fulfill the task the searcher was trying to accomplish?
Because of this focus on user satisfaction and task accomplishment, there’s no strict benchmarks on how long your content should be, how many times it should contain a keyword, or what you put in your header tags. All those can play a role in how well a page performs in search, but the focus should be on the users who will be reading the content.
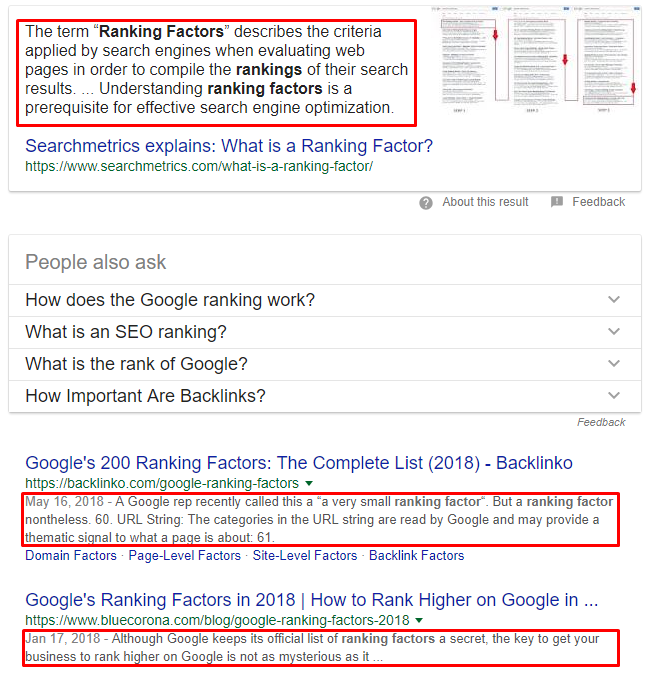
Today, with hundreds or even thousands of ranking signals, the top three have stayed fairly consistent: links to your website (which serve as a third-party credibility signals), on-page content (quality content that fulfills a searcher’s intent), and RankBrain.
What is RankBrain?
RankBrain is the machine learning component of Google’s core algorithm. Machine learning is a computer program that continues to improve its predictions over time through new observations and training data. In other words, it’s always learning, and because it’s always learning, search results should be constantly improving.
For example, if RankBrain notices a lower ranking URL providing a better result to users than the higher ranking URLs, you can bet that RankBrain will adjust those results, moving the more relevant result higher and demoting the lesser relevant pages as a byproduct.
Like most things with the search engine, we don’t know exactly what comprises RankBrain, but apparently, neither do the folks at Google.
What does this mean for SEOs?
Because Google will continue leveraging RankBrain to promote the most relevant, helpful content, we need to focus on fulfilling searcher intent more than ever before. Provide the best possible information and experience for searchers who might land on your page, and you’ve taken a big first step to performing well in a RankBrain world.
Engagement metrics: correlation, causation, or both?
With Google rankings, engagement metrics are most likely part correlation and part causation.
When we say engagement metrics, we mean data that represents how searchers interact with your site from search results. This includes things like:
- Clicks (visits from search)
- Time on page (amount of time the visitor spent on a page before leaving it)
- Bounce rate (the percentage of all website sessions where users viewed only one page)
- Pogo-sticking (clicking on an organic result and then quickly returning to the SERP to choose another result)
Many tests, including Moz’s own ranking factor survey, have indicated that engagement metrics correlate with higher ranking, but causation has been hotly debated. Are good engagement metrics just indicative of highly ranked sites? Or are sites ranked highly because they possess good engagement metrics?
What Google has said
While they’ve never used the term “direct ranking signal,” Google has been clear that they absolutely use click data to modify the SERP for particular queries.
According to Google’s former Chief of Search Quality, Udi Manber:
“The ranking itself is affected by the click data. If we discover that, for a particular query, 80% of people click on #2 and only 10% click on #1, after a while we figure out probably #2 is the one people want, so we’ll switch it.”
Another comment from former Google engineer Edmond Lau corroborates this:
“It’s pretty clear that any reasonable search engine would use click data on their own results to feed back into ranking to improve the quality of search results. The actual mechanics of how click data is used is often proprietary, but Google makes it obvious that it uses click data with its patents on systems like rank-adjusted content items.”
Because Google needs to maintain and improve search quality, it seems inevitable that engagement metrics are more than correlation, but it would appear that Google falls short of calling engagement metrics a “ranking signal” because those metrics are used to improve search quality, and the rank of individual URLs is just a byproduct of that.
What tests have confirmed
Various tests have confirmed that Google will adjust SERP order in response to searcher engagement:
- Rand Fishkin’s 2014 test resulted in a #7 result moving up to the #1 spot after getting around 200 people to click on the URL from the SERP. Interestingly, ranking improvement seemed to be isolated to the location of the people who visited the link. The rank position spiked in the US, where many participants were located, whereas it remained lower on the page in Google Canada, Google Australia, etc.
- Larry Kim’s comparison of top pages and their average dwell time pre- and post-RankBrain seemed to indicate that the machine-learning component of Google’s algorithm demotes the rank position of pages that people don’t spend as much time on.
- Darren Shaw’s testing has shown user behavior’s impact on local search and map pack results as well.
Since user engagement metrics are clearly used to adjust the SERPs for quality, and rank position changes as a byproduct, it’s safe to say that SEOs should optimize for engagement. Engagement doesn’t change the objective quality of your web page, but rather your value to searchers relative to other results for that query. That’s why, after no changes to your page or its backlinks, it could decline in rankings if searchers’ behaviors indicates they like other pages better.
In terms of ranking web pages, engagement metrics act like a fact-checker. Objective factors such as links and content first rank the page, then engagement metrics help Google adjust if they didn’t get it right.
The evolution of search results
Back when search engines lacked a lot of the sophistication they have today, the term “10 blue links” was coined to describe the flat structure of the SERP. Any time a search was performed, Google would return a page with 10 organic results, each in the same format.

In this search landscape, holding the #1 spot was the holy grail of SEO. But then something happened. Google began adding results in new formats on their search result pages, called SERP features. Some of these SERP features include:
- Paid advertisements
- Featured snippets
- People Also Ask boxes
- Local (map) pack
- Knowledge panel
- Sitelinks
And Google is adding new ones all the time. It even experimented with “zero-result SERPs,” a phenomenon where only one result from the Knowledge Graph was displayed on the SERP with no results below it except for an option to “view more results.”
The addition of these features caused some initial panic for two main reasons. For one, many of these features caused organic results to be pushed down further on the SERP. Another byproduct is that fewer searchers are clicking on the organic results since more queries are being answered on the SERP itself.
So why would Google do this? It all goes back to the search experience. User behavior indicates that some queries are better satisfied by different content formats. Notice how the different types of SERP features match the different types of query intents.
|
Query Intent |
Possible SERP Feature Triggered |
|---|---|
|
Informational |
Featured Snippet |
|
Informational with one answer |
Knowledge Graph / Instant Answer |
|
Local |
Map Pack |
|
Transactional |
Shopping |
We’ll talk more about intent in Chapter 3, but for now, it’s important to know that answers can be delivered to searchers in a wide array of formats, and how you structure your content can impact the format in which it appears in search.
Localized search
A search engine like Google has its own proprietary index of local business listings, from which it creates local search results.
If you are performing local SEO work for a business that has a physical location customers can visit (ex: dentist) or for a business that travels to visit their customers (ex: plumber), make sure that you claim, verify, and optimize a free Google My Business Listing.
When it comes to localized search results, Google uses three main factors to determine ranking:
- Relevance
- Distance
- Prominence
Relevance
Relevance is how well a local business matches what the searcher is looking for. To ensure that the business is doing everything it can to be relevant to searchers, make sure the business’ information is thoroughly and accurately filled out.
Distance
Google use your geo-location to better serve you local results. Local search results are extremely sensitive to proximity, which refers to the location of the searcher and/or the location specified in the query (if the searcher included one).
Organic search results are sensitive to a searcher’s location, though seldom as pronounced as in local pack results.
Prominence
With prominence as a factor, Google is looking to reward businesses that are well-known in the real world. In addition to a business’ offline prominence, Google also looks to some online factors to determine local ranking, such as:
Reviews
The number of Google reviews a local business receives, and the sentiment of those reviews, have a notable impact on their ability to rank in local results.
Citations
A “business citation” or “business listing” is a web-based reference to a local business’ “NAP” (name, address, phone number) on a localized platform (Yelp, Acxiom, YP, Infogroup, Localeze, etc.).
Local rankings are influenced by the number and consistency of local business citations. Google pulls data from a wide variety of sources in continuously making up its local business index. When Google finds multiple consistent references to a business’s name, location, and phone number it strengthens Google’s “trust” in the validity of that data. This then leads to Google being able to show the business with a higher degree of confidence. Google also uses information from other sources on the web, such as links and articles.
Check a local business’ citation accuracy here.
Organic ranking
SEO best practices also apply to local SEO, since Google also considers a website’s position in organic search results when determining local ranking.
In the next chapter, you’ll learn on-page best practices that will help Google and users better understand your content.
[Bonus!] Local engagement
Although not listed by Google as a local ranking determiner, the role of engagement is only going to increase as time goes on. Google continues to enrich local results by incorporating real-world data like popular times to visit and average length of visits…

…and even provides searchers with the ability to ask the business questions!

Undoubtedly now more than ever before, local results are being influenced by real-world data. This interactivity is how searchers interact with and respond to local businesses, rather than purely static (and game-able) information like links and citations.
Since Google wants to deliver the best, most relevant local businesses to searchers, it makes perfect sense for them to use real time engagement metrics to determine quality and relevance.
You don’t have to know the ins and outs of Google’s algorithm (that remains a mystery!), but by now you should have a great baseline knowledge of how the search engine finds, interprets, stores, and ranks content. Armed with that knowledge, let’s learn about choosing the keywords your content will target!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
The Rules of Link Building – Whiteboard Friday
Posted by BritneyMuller
Are you building links the right way? Or are you still subscribing to outdated practices? Britney Muller clarifies which link building tactics still matter and which are a waste of time (or downright harmful) in today’s episode of Whiteboard Friday.
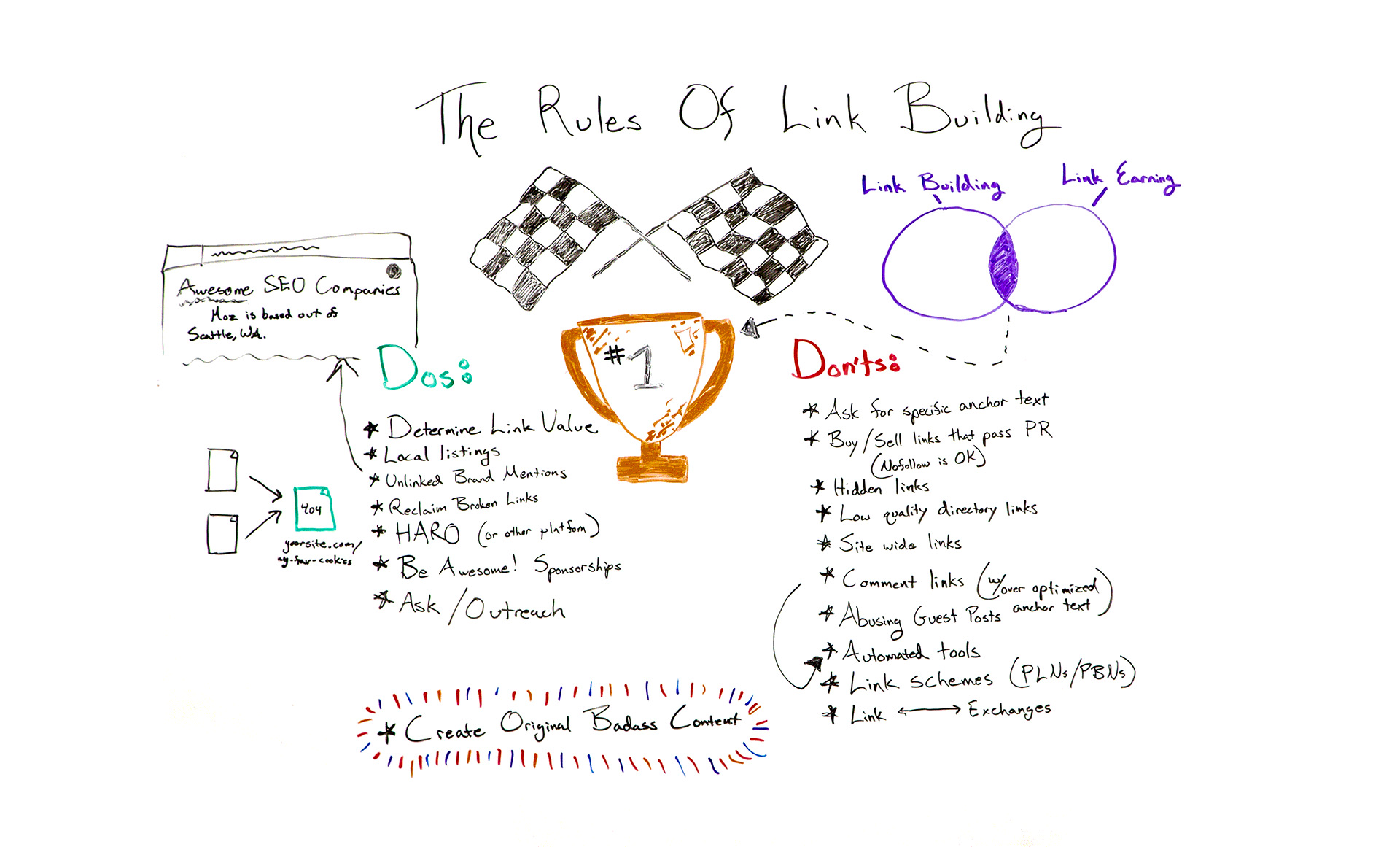
Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Happy Friday, Moz fans! Welcome to another edition of Whiteboard Friday. Today we are going over the rules of link building. It’s no secret that links are one of the top three ranking factors in Goggle and can greatly benefit your website. But there is a little confusion around what’s okay to do as far as links and what’s not. So hopefully, this helps clear some of that up.
The Dos
All right. So what are the dos? What do you want to be doing? First and most importantly is just to…
I. Determine the value of that link. So aside from ranking potential, what kind of value will that link bring to your site? Is it potential traffic? Is it relevancy? Is it authority? Just start to weigh out your options and determine what’s really of value for your site.
II. Local listings still do very well. These local business citations are on a bunch of different platforms, and services like Moz Local or Yext can get you up and running a little bit quicker. They tend to show Google that this business is indeed located where it says it is. It has consistent business information — the name, address, phone number, you name it. But something that isn’t really talked about all that often is that some of these local listings never get indexed by Google. If you think about it, Yellowpages.com is probably populating thousands of new listings a day. Why would Google want to index all of those?
So if you’re doing business listings, an age-old thing that local SEOs have been doing for a while is create a page on your site that says where you can find us online. Link to those local listings to help Google get that indexed, and it sort of has this boomerang-like effect on your site. So hope that helps. If that’s confusing, I can clarify down below. Just wanted to include it because I think it’s important.
III. Unlinked brand mentions. One of the easiest ways you can get a link is by figuring out who is mentioning your brand or your company and not linking to it. Let’s say this article publishes about how awesome SEO companies are and they mention Moz, and they don’t link to us. That’s an easy way to reach out and say, “Hey, would you mind adding a link? It would be really helpful.”

IV. Reclaiming broken links is also a really great way to kind of get back some of your links in a short amount of time and little to no effort. What does this mean? This means that you had a link from a site that now your page currently 404s. So they were sending people to your site for a specific page that you’ve since deleted or updated somewhere else. Whatever that might be, you want to make sure that you 301 this broken link on your site so that it pushes the authority elsewhere. Definitely a great thing to do anyway.

V. HARO (Help a Reporter Out). Reporters will notify you of any questions or information they’re seeking for an article via this email service. So not only is it just good general PR, but it’s a great opportunity for you to get a link. I like to think of link building as really good PR anyway. It’s like digital PR. So this just takes it to the next level.
VI. Just be awesome. Be cool. Sponsor awesome things. I guarantee any one of you watching likely has incredible local charities or amazing nonprofits in your space that could use the sponsorship, however big or small that might be. But that also gives you an opportunity to get a link. So something to definitely consider.
VII. Ask/Outreach. There’s nothing wrong with asking. There’s nothing wrong with outreach, especially when done well. I know that link building outreach in general kind of gets a bad rap because the response rate is so painfully low. I think, on average, it’s around 4% to 7%, which is painful. But you can get that higher if you’re a little bit more strategic about it or if you outreach to people you already currently know. There’s a ton of resources available to help you do this better, so definitely check those out. We can link to some of those below.
VIII. COBC (create original badass content). We hear lots of people talk about this. When it comes to link building, it’s like, “Link building is dead. Just create great content and people will naturally link to you. It’s brilliant.” It is brilliant, but I also think that there is something to be said about having a healthy mix. There’s this idea of link building and then link earning. But there’s a really perfect sweet spot in the middle where you really do get the most bang for your buck.

The Don’ts
All right. So what not to do. The don’ts of today’s link building world are…
I. Don’t ask for specific anchor text. All of these things appear so spammy. The late Eric Ward talked about this and was a big advocate for never asking for anchor text. He said websites should be linked to however they see fit. That’s going to look more natural. Google is going to consider it to be more organic, and it will help your site in the long run. So that’s more of a suggestion. These other ones are definitely big no-no’s.
II. Don’t buy or sell links that pass PageRank. You can buy or sell links that have a no-follow attached, which attributes that this is paid-for, whether it be an advertisement or you don’t trust it. So definitely looking into those and understanding how that works.
III. Hidden links. We used to do this back in the day, the ridiculous white link on a white background. They were totally hidden, but crawlers would pick them up. Don’t do that. That’s so old and will not work anymore. Google is getting so much smarter at understanding these things.
IV. Low-quality directory links. Same with low-quality directory links. We remember those where it was just loads and loads of links and text and a random auto insurance link in there. You want to steer clear of those.
V. Site-wide links also look very spammy. Site wide being whether it’s a footer link or a top-level navigation link, you definitely don’t want to go after those. They can appear really, really spammy. Avoid those.
VI. Comment links with over-optimized anchor link text, specifically, you want to avoid. Again, it’s just like any of these others. It looks spammy. It’s not going to help you long term. Again, what’s the value of that overall? So avoid that.
VII. Abusing guest posts. You definitely don’t want to do this. You don’t want to guest post purely just for a link. However, I am still a huge advocate, as I know many others out there are, of guest posting and providing value. Whether there be a link or not, I think there is still a ton of value in guest posting. So don’t get rid of that altogether, but definitely don’t target it for potential link building opportunities.
VIII. Automated tools used to create links on all sorts of websites. ScrapeBox is an infamous one that would create the comment links on all sorts of blogs. You don’t want to do that.
IX. Link schemes, private link networks, and private blog networks. This is where you really get into trouble as well. Google will penalize or de-index you altogether. It looks so, so spammy, and you want to avoid this.
X. Link exchange. This is in the same vein as the link exchanges, where back in the day you used to submit a website to a link exchange and they wouldn’t grant you that link until you also linked to them. Super silly. This stuff does not work anymore, but there are tons of opportunities and quick wins for you to gain links naturally and more authoritatively.
So hopefully, this helps clear up some of the confusion. One question I would love to ask all of you is: To disavow or to not disavow? I have heard back-and-forth conversations on either side on this. Does the disavow file still work? Does it not? What are your thoughts? Please let me know down below in the comments.
Thank you so much for tuning in to this edition of Whiteboard Friday. I will see you all soon. Thanks.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!